スクレイピングしたデータを分析することがよくあると思いますが、pandasはurlやhtmlを指定するとtableタグを自動で見つけてDataFrameに格納してくれます。逆にDataFrameの内容をhtmlのtableで出力することも可能です。
read_html htmlからDataFrameを生成する
read_htmlメソッドを使用すると、htmlからDataFrameを生成することができます。
事前準備
予め依存するhtmlパーサのモジュールをインストールします。
pip install lxml pip install bs4 pip install html5lib
urlを指定する
read_htmlメソッドの引数にurlを指定すると、httpアクセスを行いhtmlを取得しtableタグの中身をDataFrameに格納してくれます。
試しに気象庁のサイトのランキングデータを取得してみましょう。
http://www.data.jma.go.jp/obd/stats/etrn/view/rankall.php?prec_no=&block_no=&year=2017&month=&day=&view=
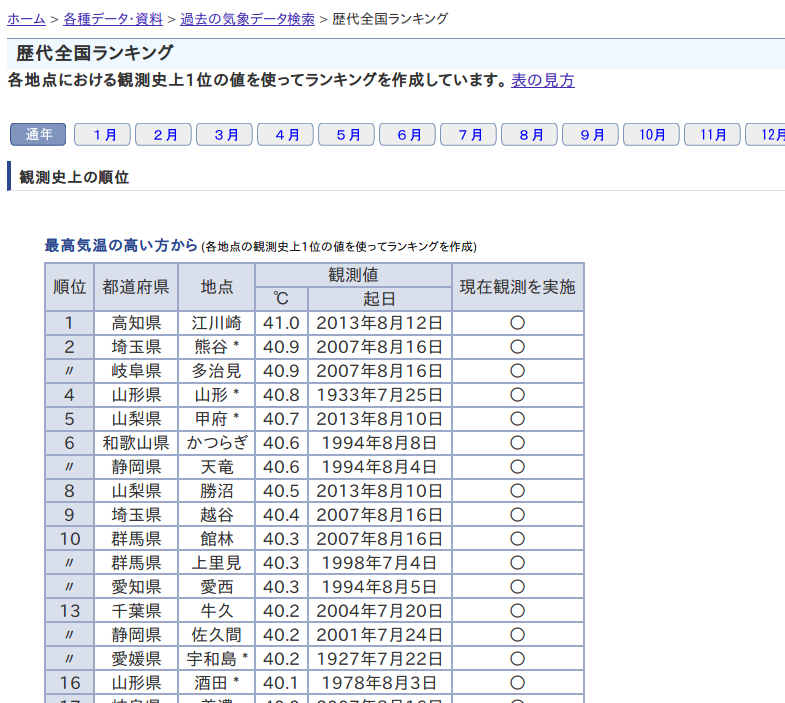
複数のtableがありますが、シーケンスで取得できます。一番上のtableを取得する場合は0を指定します。
dfs = pd.read_html('http://www.data.jma.go.jp/obd/stats/etrn/view/rankall.php?prec_no=&block_no=&year=2017&month=&day=&view=', header=1)
df = dfs[0]
# 0 1 2 3 4 5
# 0 順位 都道府県 地点 観測値 現在観測を実施 NaN
# 1 ℃ 起日 NaN NaN NaN NaN
# 2 1 高知県 江川崎 41.0 2013年8月12日 ○
# 3 2 埼玉県 熊谷 * 40.9 2007年8月16日 ○
# 4 〃 岐阜県 多治見 40.9 2007年8月16日 ○
# 5 4 山形県 山形 * 40.8 1933年7月25日 ○
# 6 5 山梨県 甲府 * 40.7 2013年8月10日 ○
# 7 6 和歌山県 かつらぎ 40.6 1994年8月8日 ○
# 8 〃 静岡県 天竜 40.6 1994年8月4日 ○
# 9 8 山梨県 勝沼 40.5 2013年8月10日 ○
# 10 9 埼玉県 越谷 40.4 2007年8月16日 ○
# :
# :
cssやxpath形式で指定するよりも遥かに簡単にデータが取得できました。
htmlを指定する
tableタグ以外にもデータの表題などを取得したい場合があるかと思いますが、htmlを引数に指定することも可能です。requestsなどでhtmlを取得しtableはpandasで取得し、その他はbs4などでパースする、という方法も可能です。htmlを指定する場合は以下のように書き換えることができます。
r = requests.get('http://www.data.jma.go.jp/obd/stats/etrn/view/rankall.php?prec_no=&block_no=&year=2017&month=&day=&view=')
r.encoding = 'UTF-8'
html = r.text
dfs = pd.read_html(html)
request、bs4については以下を参照してください。
requestsの使い方 webサイトのデータを取得する
beautifulsoup4 htmlをパース、スクレイピングする その1
beautifulsoup4 htmlをパース、スクレイピングする その2
htmlを出力する
htmlに出力することも可能です。分析結果をwebに出力する場合などに重宝するでしょう。
df.to_html('sample.html')
引数に出力ファイル名を指定するだけでhtmlのtableで出力することができます。


