このページではmatplotlibを使用してヒストグラムを描画する方法について解説します。サンプルはOO形式と呼ばれる書き方となっています。figure、axesについて知らない方は事前に以下を一読することをおすすめします。
matplotlib入門
matplotlibの基本 figureとaxes
Contents
ヒストグラムの基本
簡単なサンプル
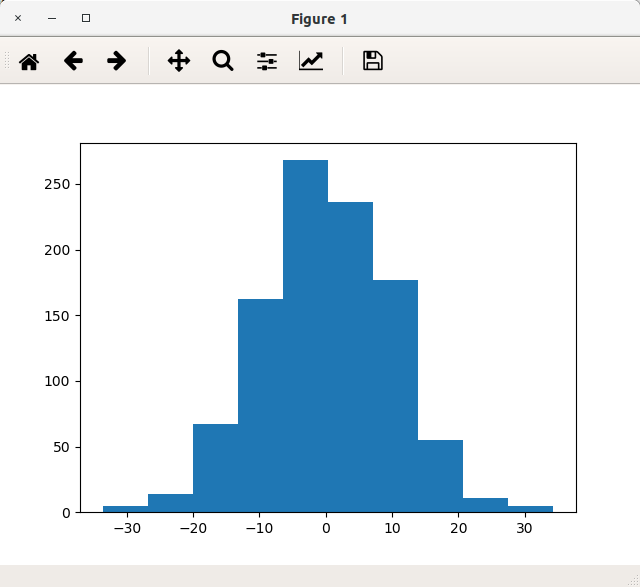
まずは最低限、簡単なサンプルからです。以下のサンプルでは平均0、標準偏差10の正規乱数を1000個生成し、ヒストグラムで表示しています。
import matplotlib.pyplot as plt import numpy as np # 対象データ(平均0、標準偏差10の正規乱数を1000個生成) x = np.random.normal(0, 10, 1000) # figureを生成する fig = plt.figure() # axをfigureに設定する ax = fig.add_subplot(1, 1, 1) # axesにplot ax.hist(x, bins=10) # 表示する plt.show()
実行結果
オプション
最低限の表示ができたところで、オプションについて解説します。以下、hist()の代表的なオプションです。
| パラメータ | 説明 |
|---|---|
| x(必須) | データ配列 |
| bins | 階級数(デフォルト値: 10) |
| range | 表示する階級の範囲(最大と最小を指定) |
| density | Trueを指定すると面積が1となるように正規化(デフォルト値:False) |
| cumulative | Trueを指定すると累積化(デフォルト値:False) |
| color | 色 |
| ec | 境界色 |
| alpha | 透明度(0〜1を指定、0:完全透明、1:不透明) |
それでは、上記オプションを踏まえて様々なヒストグラムを作成してみましょう。
bins 階級数
binsを指定すると階級数を指定することができます。また、リストなどの配列を指定するとその配列を階級とすることができます。スタージェスの公式で自動的に階級分けすることもできます。上のコードのbinsの値を以下の通り変更してみます。つまり、階級数を20にするわけですね。
ax.hist(x, bins=20)
実行結果
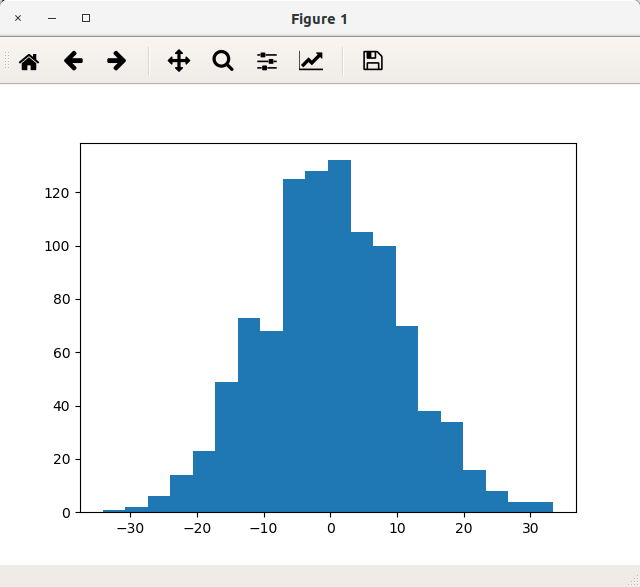
このように階級幅が細かくなったことが確認できます。また、文字列autoを指定するとスタージェスの公式若しくはフリードマン=ダイアコニスの法則の公式が適用されます。
density 正規化
densityにTrueを指定すると、面積1に調整してくれるため、十分大きいサンプルで階級数を増やすと確率密度関数に近づけることができます。実際、density=Trueのヒストグラムと平均0、標準偏差10の正規分布の確率密度関数を重ねて表示すると、以下の通り十分近いかたちが得られます。
import matplotlib.pyplot as plt import numpy as np from scipy.stats import norm # 対象データ(平均0、標準偏差10の正規乱数) x = np.random.normal(0, 10, 10000) # figureを生成する fig = plt.figure() # axをfigureに設定する ax = fig.add_subplot(1, 1, 1) # axesにplot ax.hist(x, bins=30, density=True) # 対象データ(平均0、標準偏差10の正規分布の確率密度関数のグラフ) X = np.linspace(-50, 50, 100) Y = norm.pdf(X, loc=0, scale=10) ax.plot(X, Y, c="red") # 表示する plt.show()
実行結果
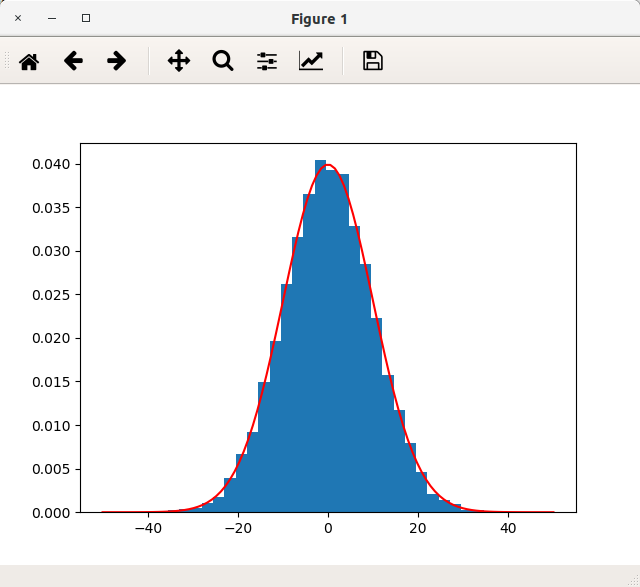
このようにdensityを指定するとヒストグラムで確率的に可視化することができます。
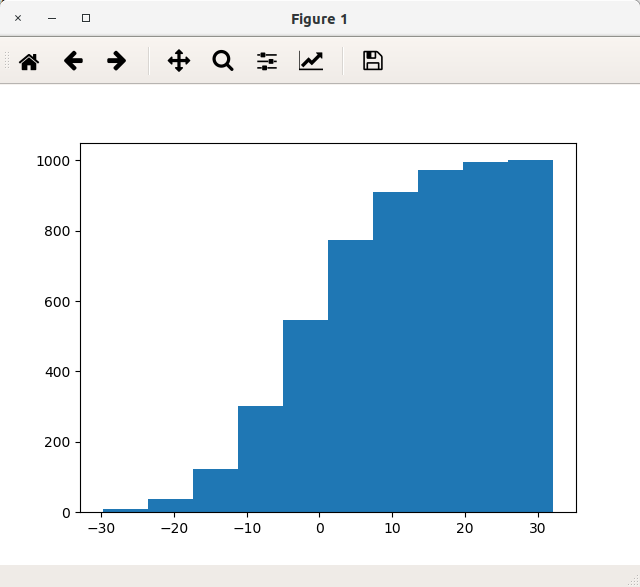
cumulative 累積ヒストグラム
cumulative=Trueを指定すると、累積ヒストグラムを作成することができます。最初のサンプルから以下の通り修正してみます。
ax.hist(x, cumulative=True)
実行結果
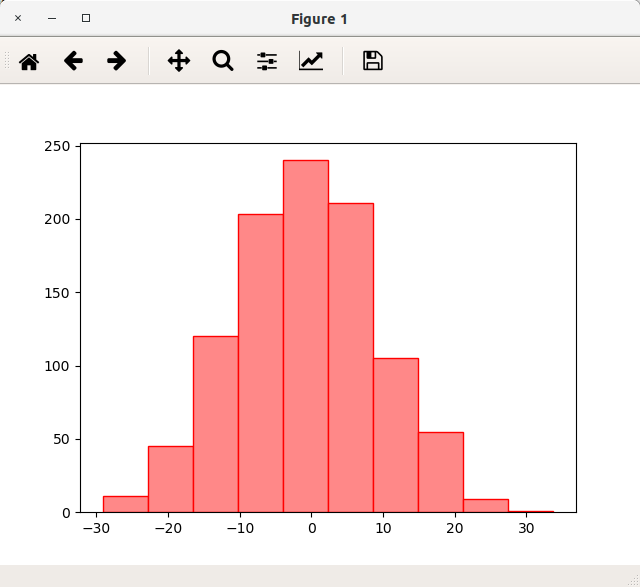
色と境界線
color、ecを指定すると、色・境界色を指定することができます。最初のサンプルから以下の通り修正してみます。
ax.hist(x, color="#FF8888")
実行結果
重ね合わせと透明度
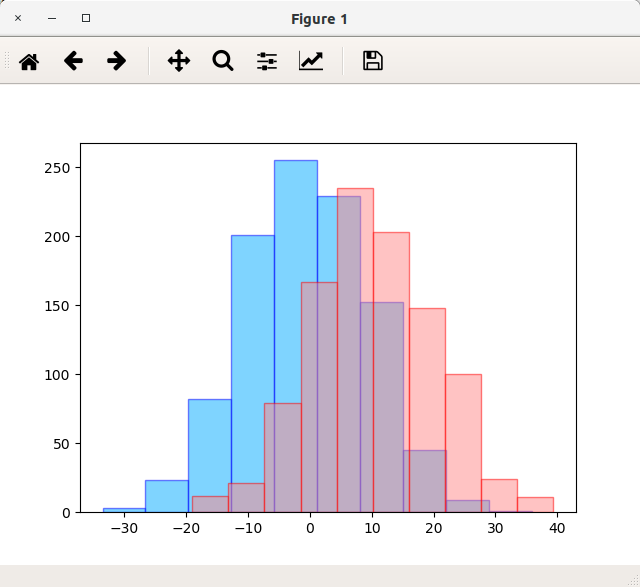
また、複数系列を重ねることもできますが、この際、alphaを指定して透明度を調整すると重複範囲が見やすくなります。以下のサンプルは2種類の正規乱数のヒストグラムを重ねて表示しています。
import matplotlib.pyplot as plt import numpy as np # 対象データ1(平均0、標準偏差10の正規乱数を1000個生成) x1 = np.random.normal(0, 10, 1000) # 対象データ2(平均10、標準偏差10の正規乱数を1000個生成) x2 = np.random.normal(10, 10, 1000) # figureを生成する fig = plt.figure() # axをfigureに設定する ax = fig.add_subplot(1, 1, 1) # axesにplot ax.hist(x1, color="#00AAFF", ec="#0000FF", alpha=0.5) ax.hist(x2, color="#FF8888", ec="#FF0000", alpha=0.5) # 表示する plt.show()
実行結果