
統計分析を学習する前に、準備運動としてデータの種類や扱い方について簡単におさらいしておきましょう。
データの種類
業務上、統計分析で扱うデータは検索や売上等の業務データやサーバーのログ、顧客アンケート等多岐にわたります。そのれらの統計データですが、様々な切り口で分類することができます。
量的データと質的データ
量的データは気温や売れた商品の価格・数量、アクセス数等といった通常数値で表される値です。一方、質的データとは顧客の性別や出身地といった通常文字列で表される値です。本講座では量的データをメインに取り扱います。
- 量的データ・・・身長、体重、アクセス数、時間など
- 質的データ・・・性別、出身地、血液型など
また、アンケートなどで1:満足、2:どちらでもない、3:不満 といった選択肢を見かけますが、こういったデータは順序尺度と呼ばれ、順序付き数値ではあるものの演算ができないため質的データとして扱われます。
データの次元
データの次元という分類方法もあります。例えば、以下のような1項目しかないデータは一次元のデータと呼びます。本講座では1次元のデータをメインで取り扱います。
| がく片の長さ |
|---|
| 5 |
| 6.4 |
| 6.5 |
| 6.7 |
| 6.3 |
| 4.6 |
| : |
また、以下のように複数の項目があるデータをN次元データと呼びます。多数の次元同士の相関やクラスターを取り扱う統計分析を多変量解析と呼びます。
| がく片 | がく片幅 | 花びら | 花びら幅 | 名前 |
|---|---|---|---|---|
| 5 | 3.3 | 1.4 | 0.2 | セトナ |
| 6.4 | 2.8 | 5.6 | 2.2 | バージニカ |
| 6.5 | 2.8 | 4.6 | 1.5 | バーシクル |
| 6.7 | 3.1 | 5.6 | 2.4 | バージニカ |
| 6.3 | 2.8 | 5.1 | 1.5 | バージニカ |
| 4.6 | 3.4 | 1.4 | 0.3 | セトナ |
| : | : | : | : | : |
データの読み込みと扱い
よく見られるデータの分析フロー
Pythonでデータ分析を行う場合、以前紹介したpandas、numpy、scipy、matplotlibを使い分けて作業を行います。以下、簡単にpandas、numpyの使い分けについて解説します。
分析の方法は人によるので無数にありますが、Pythonを使う場合、最初は以下のような流れで作業する場合が多いかと思います。
- CSVやDBを読み込みpandasのDataFrameに変換
- データクレンジング、必要なデータを抽出
- 統計計算や可視化のためndarrayに変換
- numpy、scipyで統計計算、matplotlibで可視化
まず、分析対象のデータをCSVやDBから読み取りpandasのDataFrameに変換します。DataFrameは表計算のような処理ができるため、データクレンジングや分析となるデータを抽出したり加工したりすることが簡単にできます。一方、統計計算や可視化といった数値関連の処理はnumpyの配列(ndarray)に変換して処理することが多いです。(DataFrameのままでも統計計算や可視化が可能です。)
そして、統計処理の結果の出力に必要に応じて再度pandasのDataFrameに変換しCSVやDBに出力したりレポートとしてpdfに出力したりします。
irisデータセットを扱ってみる
それでは練習としてirisデータセットをPython上で動かしてみましょう。irisデータセットとは、セトナ、バーシクル、バージニカという3種類のiris(アヤメ)の計測値(がく片長、がく片幅、花びら長、花びら幅、種類)データで、イギリスの統計学者フィッシャーが取りまとめたものです。多くの統計系ライブラリに学習用に同梱されています。先程の説明で使用したデータもirisデータセットの一部です。
今回はpandasに入っているものを使ってみましょう。以下のCSVファイルをwget等でダウンロードしてください。
まず、ダウンロードしたcsvをpandasで読み込んでDataFrameを生成します。
import pandas as pd
df = pd.read_csv('iris.csv')
中身を確認してみましょう。以下のような表形式のデータが作成されます。前回紹介したSpyderを利用されている方は、変数エクスプローラのdfをダブルクリックしてみてください。
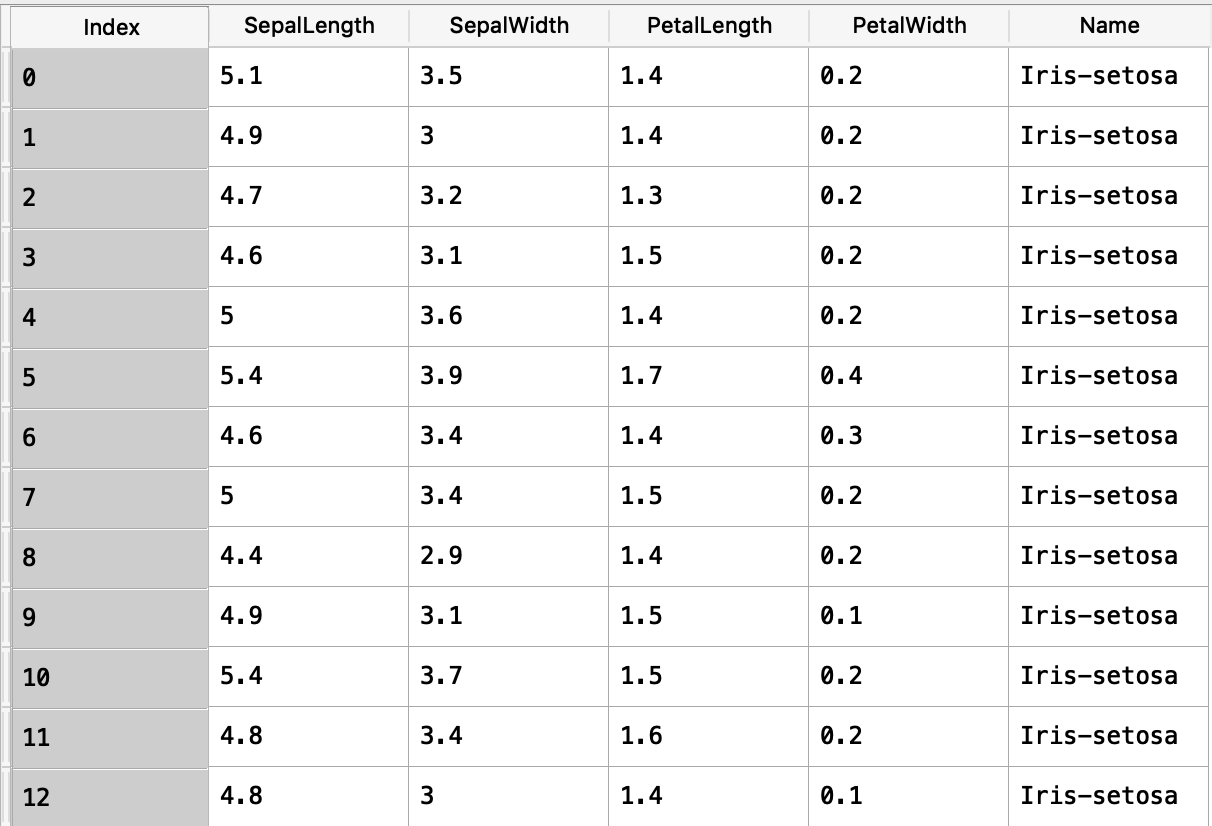
それぞれのカラムの意味は以下の通りとなります。
SepalLength:がく片長
SepalWidth:がく片幅
PetalLength:花びら長
PetalWidth:花びら幅
Species:種類
SepalLength〜PetalWidthが量的データ、最後のSpeciesが質的データとなります。
次に、がく片長さ(SepalLength)について統計値として平均を計算してみたいと思います。先程のコードの続きです。
import numpy as np data = np.array(df["SepalLength"]) np.mean(data) # 5.8433...
上のコードでは、SepalLength列を抽出し、ndarrayに変換後、numpyのmean関数で平均値の算出を行っています。確率密度関数の計算といった専門的な統計計算ではscipyを使ったり、時系列の計算で移動平均を算出する場合はpandasを使ったりします。ここらへんの使い分けは時と場合によります。
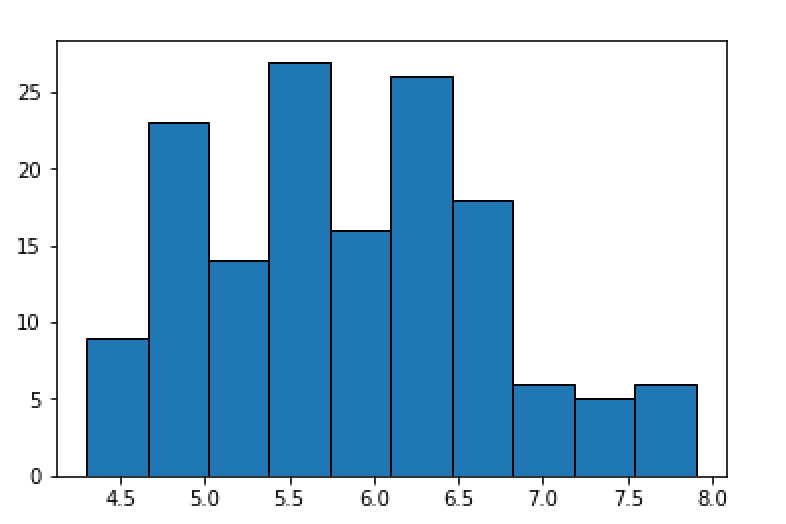
次に可視化をしてみましょう。がく片長さを階級数10のヒストグラムを作成してみます。先程のコードの続きです。
import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.hist(data, bins=10, histtype='barstacked', ec='black') plt.show()
実行すると、以下のグラフが出力されます。
量的データと、質的データデータの次元、よく使うライブラリの簡単な使い分けの解説をしました。次回からPythonを利用して統計分析について解説していきたいと思います。


